Multiple Data Sources
Connect and collate enterprise data from 50+ sources & databases
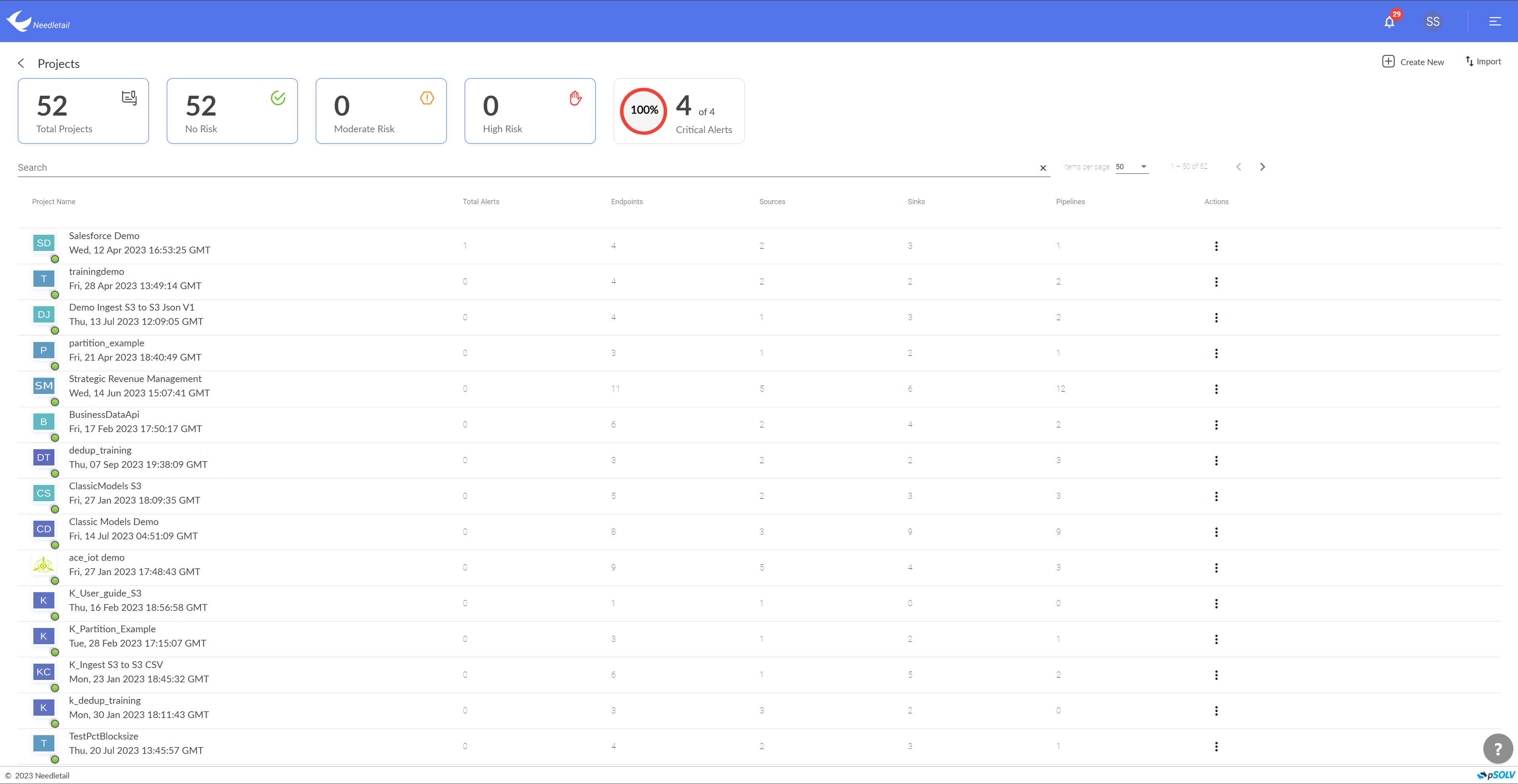
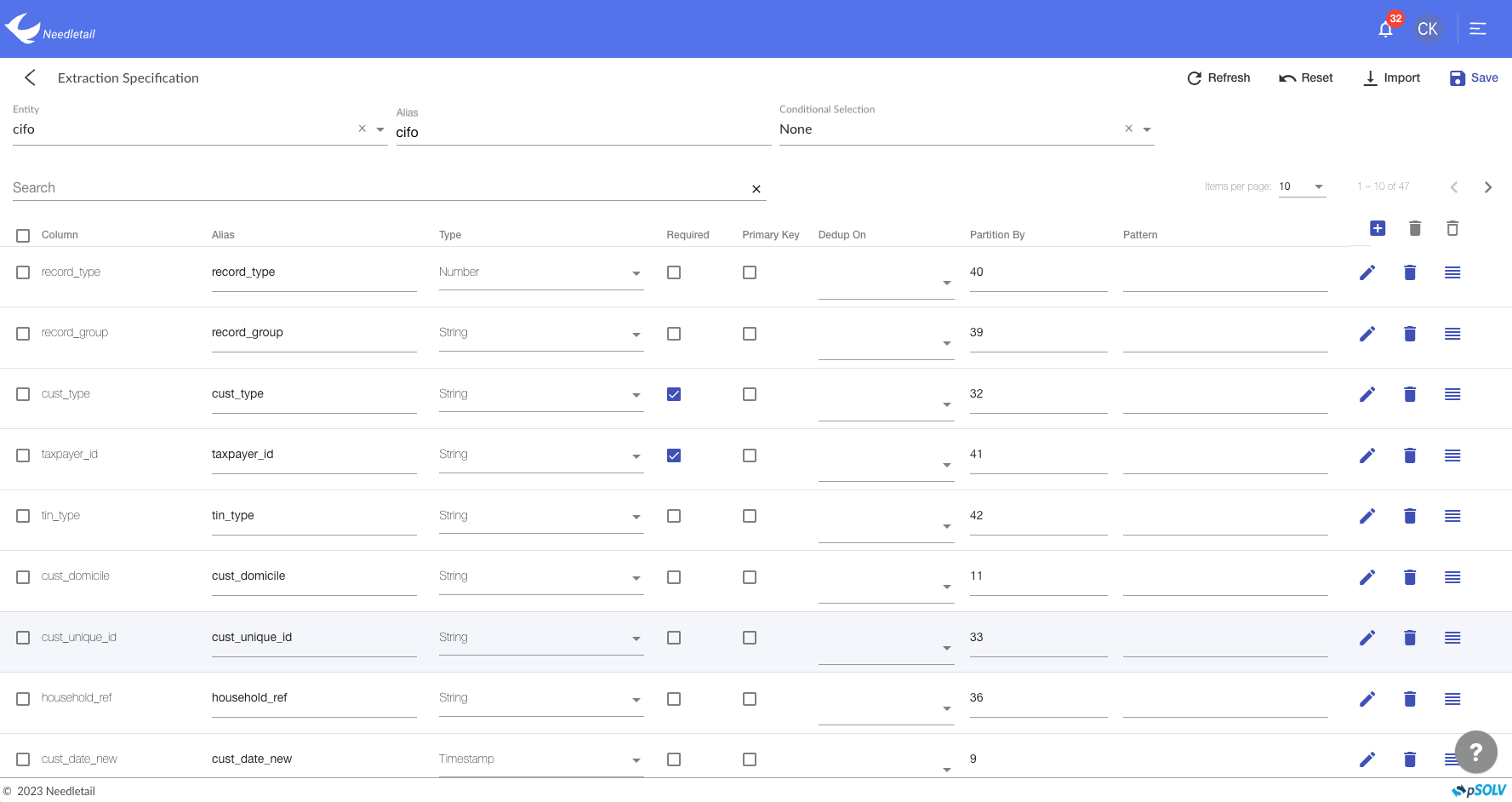
Bring in and store highly-diversified data in a format as close as the raw data in a central repository.
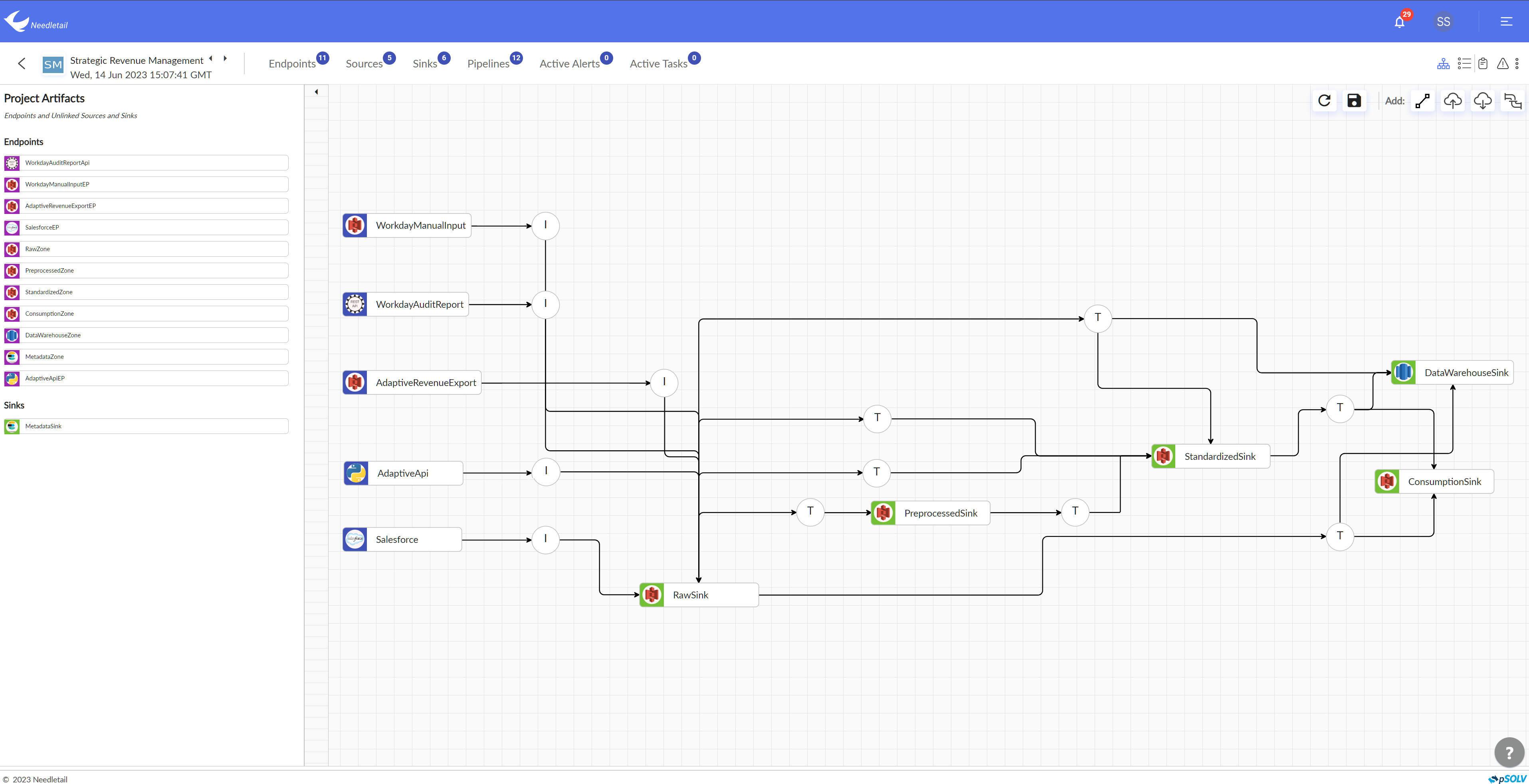
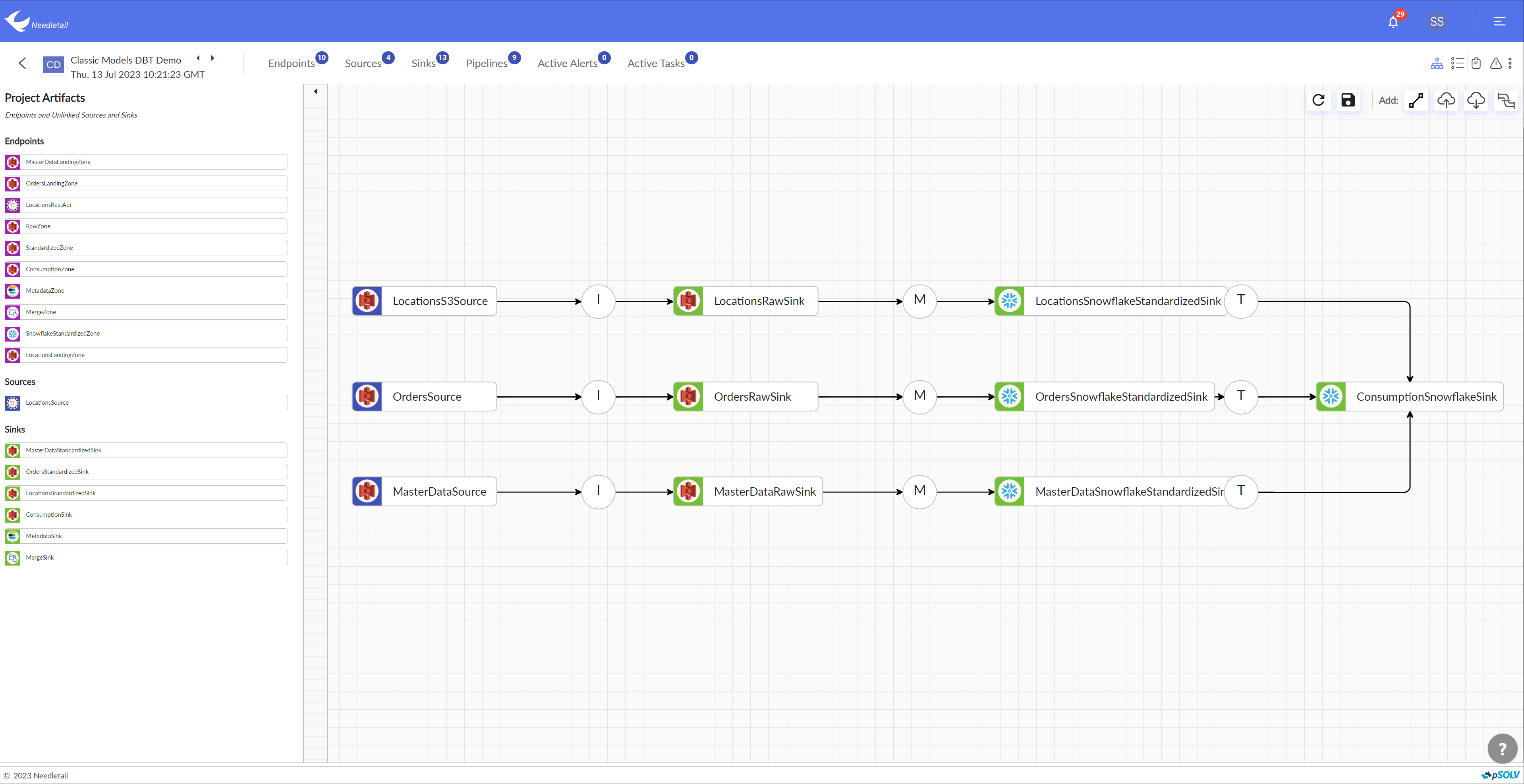
Developing A Data Lake
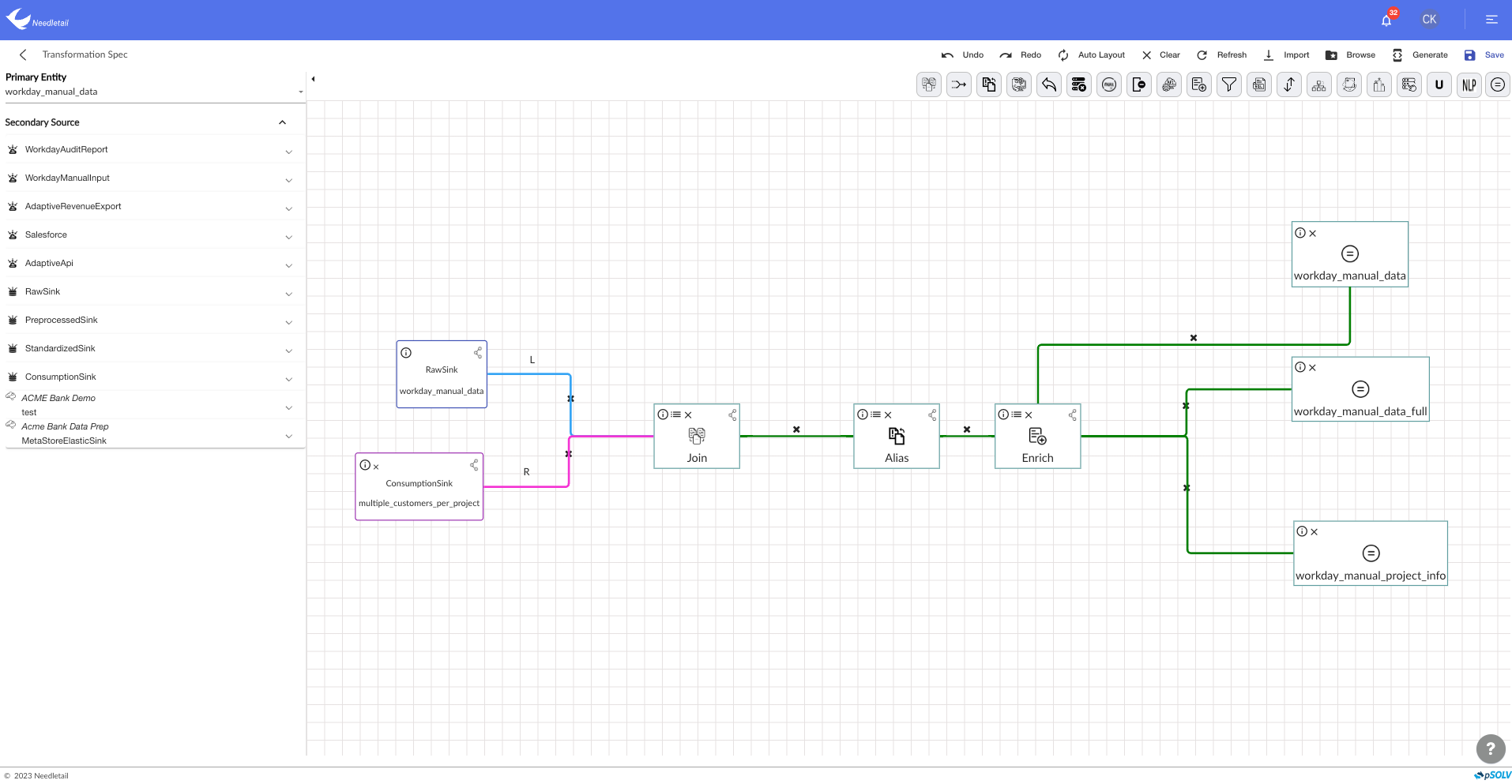
Generate data-processing pipeline In one click
Eliminate the upfront costs of ingestion & transformation of zettabytes of data with an automatic interface.
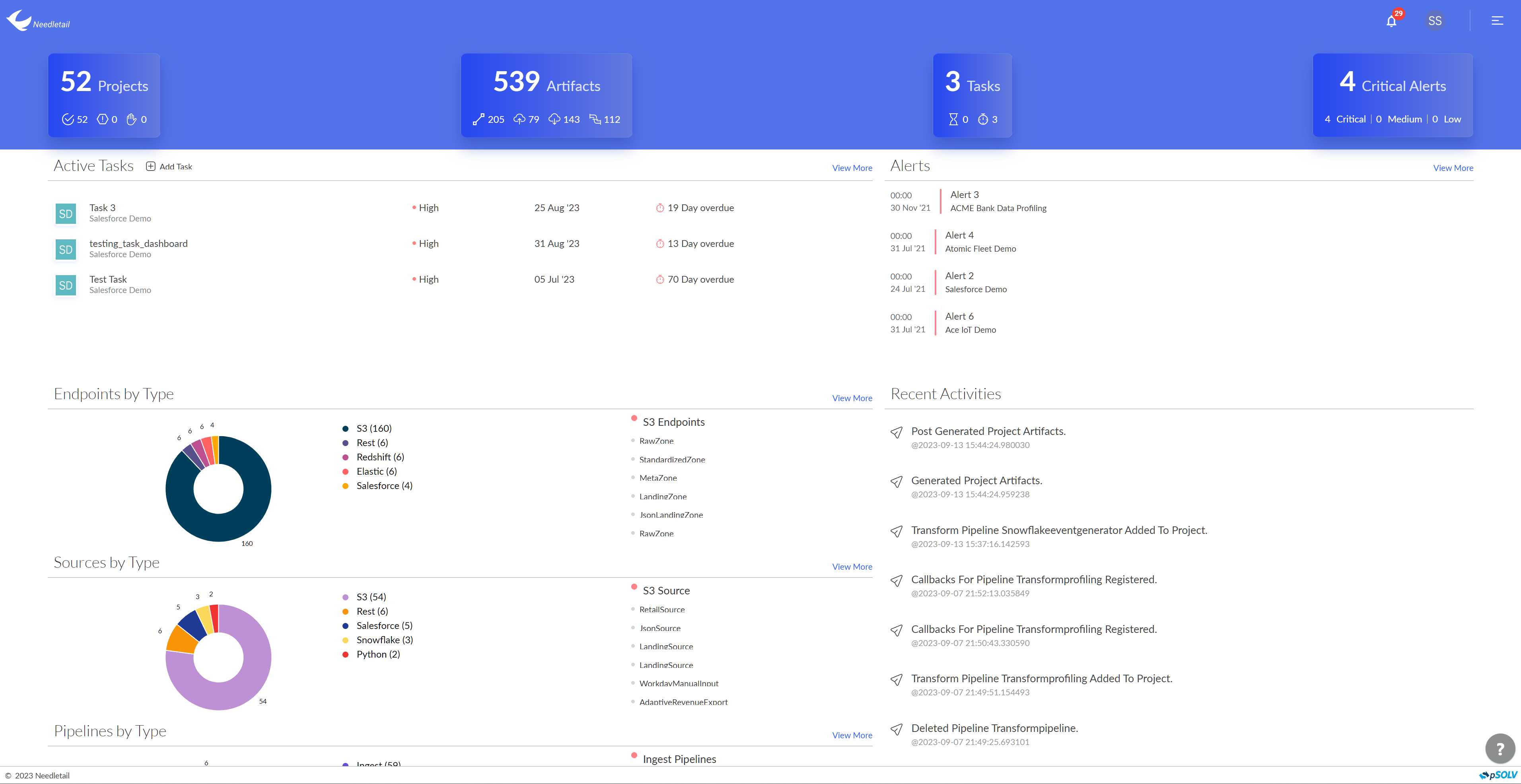
Analytics & Visualisation
Translate information into data-driven decisions with Tableau
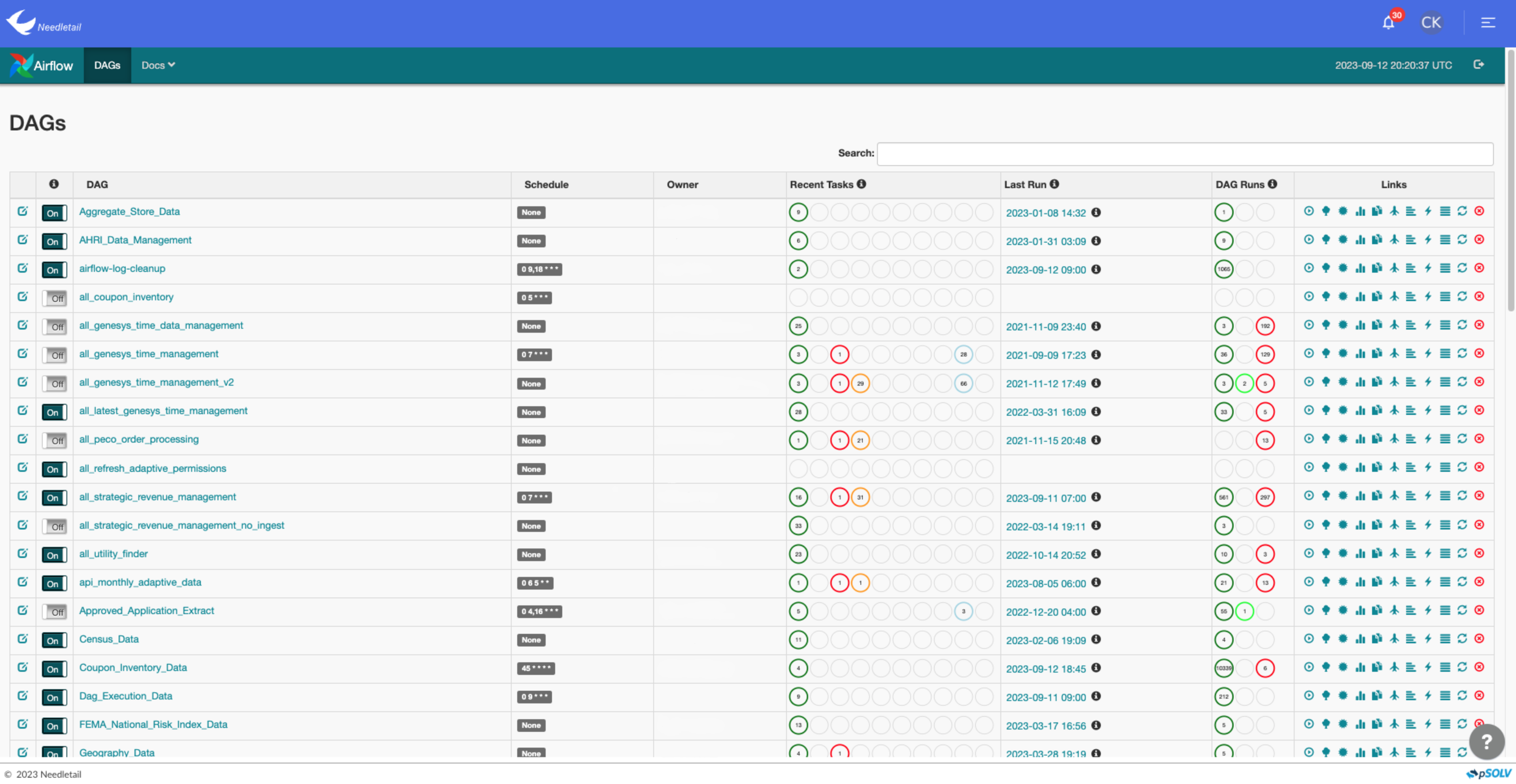
Find all of your data in one place and uncover hidden insights that you might have never seen in individual reports.