
I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail
–Abraham Maslow
We all have heard this but the contrary is equally problematic. What if you have a lot of tools?
I came to the realization that I am not much of a handyman when it comes to fixing things but it took a few misadventures and a sizable accumulation of expensive tools to realize that. I spent hours in hardware stores shopping for tools. In particular, shopping for drill bits was painfully confusing. First there is the choice between metric and imperial sizes, then there are choices with tips, brands and finally the surface on which the bit will be used.
Anyways, the point is, your tool shed may have all the tools in the world but they are of no use if you don’t know when, where and how to use them. Big Data Technology is similar. There is a wide array of technology choices, some seemingly doing the same work. Meanwhile, there are newer ones on the horizon to do things faster and better.
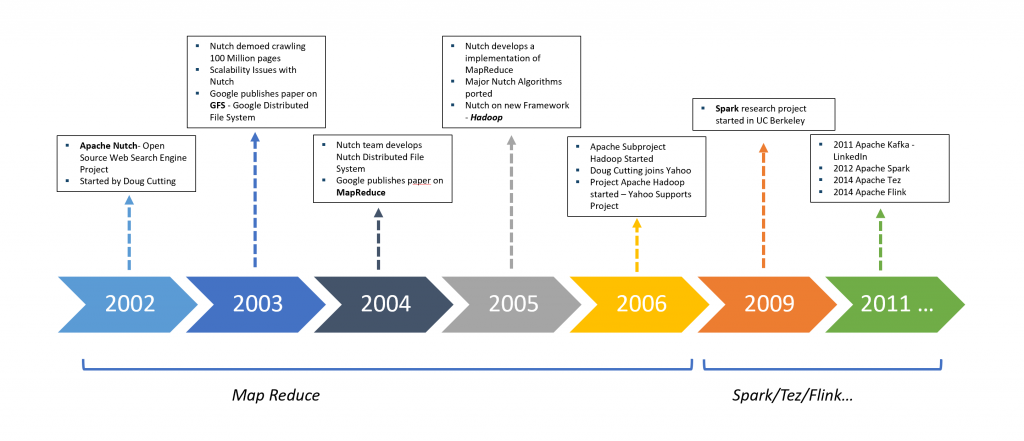
Apache Hadoop is the grandparent of all Big Data processing technologies. The biggest problems in processing Big Data was processing horsepower and storage coupled with the increase in data volume over time. Hadoop overcame these by using a cluster of computing nodes (minimally just two general-purpose laptops) and it enabled horizontal scaling of both storage and compute power by adding nodes (add another laptop to the cluster).
Claims of Hadoop’s demise are quite common but one or more fundamentals of Hadoop lives in every big data processing technology.
Hadoop started as a simple three-layer technology stack but over the years, the stack has got numerous variations and is difficult to represent all of them in a single illustration.
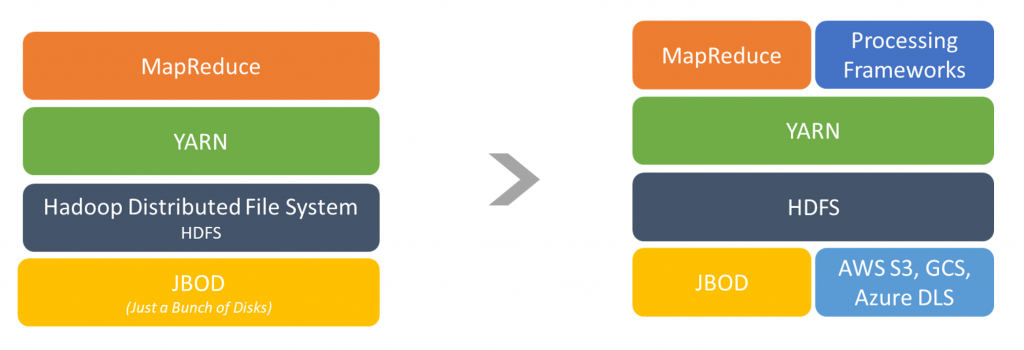
Hadoop started with three key layers: HDFS for Storage layer, YARN for Resource Management and MapReduce for processing. Storage was tightly coupled with processing. That is, if one wanted to add more storage, he or she had to add one or more computing nodes that had storage. The use of block storage and virtual compute nodes decoupled storage and compute and today horizontal scaling of either one is possible without scaling the other.
MapReduce programs have two modules: a map procedure, which performs filtering and sorting, and a reduce procedure, which performs a summary operation. Now MapReduce has two issues. One, it is Java based and needs people with expertise in Java to write Mappers and Reducers and two, it is disk I/O intensive that slows operations.
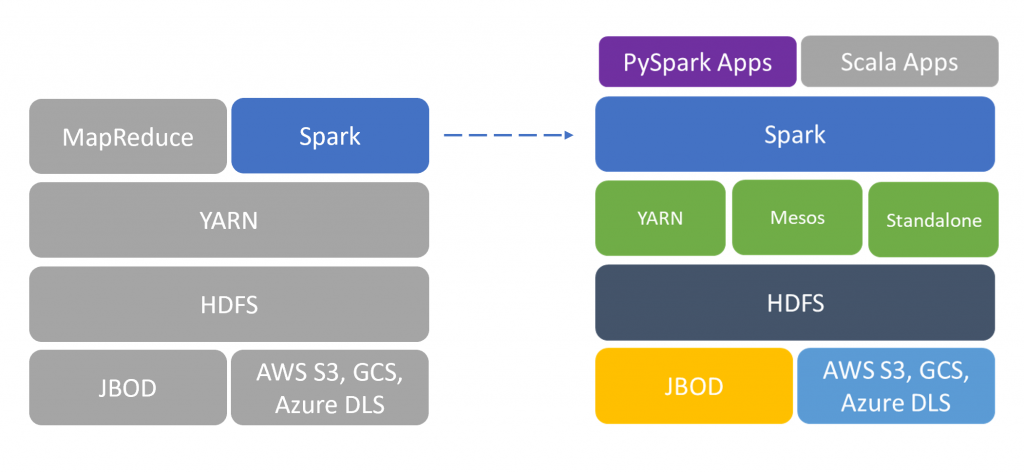
Querying layers like HIVE and scripting languages like PIG circumvented the issue of writing MapReduce programs but internally they used MapReduce. Newer technologies like Apache Spark, Apache Flink, Apache Tez addressed one or both these issues with in-memory processing and/or by using a general-purpose programming language.
And what about large volumes of streaming Data? Apache Kafka is the streaming platform of choice to get data reliably between systems or applications. Kafka, together with Spark Streaming or Flink, can provide solutions that transform real-time streaming data.
With multiple options available for each requirement, selection of the right technology stack gets complicated in the Big Data world. For example, Yarn, Mesos or Standalone Spark are the resource manager choices available for Spark, and you can use either Python, Java or Scala to build your data processing pipelines using Spark. The same is true with Flink.
Then there are the cloud service providers. AWS has EMR, Azure has HDInsight and Google has Dataproc for clusters. They also provide their own platforms and tools in addition support open source platforms and tools.
Here is an illustration of things you would need to consider when choosing your technology.
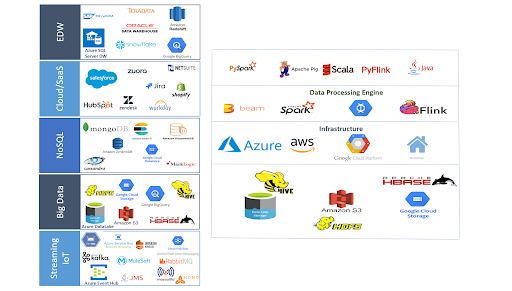
As you see, your choices are manifold and it can be as painfully confusing as buying a drill bit from the hardware store.
When it comes to big data technology choices, there are, as mentioned before, numerous permutations and combinations of solutions. You have choices in layers you chose for the stack and also choices in what goes in each layer. The other dilemma is – what if I build today and things change tomorrow? Would I have an easy migration? My answer is, if you are going to invest significant effort and money, invest a small fraction of it to get expert advice. Also, let business needs drive technology decisions.
Fill in your details to experience Needletail in action