
Met a friend who works for a large IT services organization recently. During our conversation, I mentioned that I now work for a boutique company that specialized in Big Data – both products and services. He was concerned and with all earnestness, said, “It is all hype, how come you bought into it?”
I was perplexed and we went through use cases which I thought could be ideally served by Big Data based solutions, but he wasn’t convinced. Finally, he told me about a project for a customer, a global telecom service provider, who had spent several millions of dollars on a big data solution that did not deliver. After getting a bit more detail, my inference was that they did everything right except for one minor misunderstanding of what big data is and how it can deliver. Given the numerous tasks of data integration and the churn in big data related technologies, it is easy to choose big data technology for the wrong problem or the wrong technologies for a big data solution.
Before diving into why Big Data Solutions may or may not be for you, let us distinguish between three terms that are frequently used in a Big Data discussion. They are all related, but each can potentially exist without the other. They are big data, big data technology and big data architecture – specifically data lake. Each of these could manifest themselves in different forms and identifiable names and are individually, quite commonly, used to denote Big Data.
Big Data, from purely a data characteristics point of view, is a large volume of data which by its very nature cannot be efficiently processed by conventional systems. Enterprise data which are structured, log files from large data farms, events emitted by real-time systems which are semi-structured, and social media feeds like tweets which are unstructured are all Big Data.
Big Data is data in all conceivable forms characterized by three (or maybe four or five) V’s: Volume, Velocity and Variety. Volume and Velocity of Data are not new phenomena of data. Since the inception of computing, there has always been more data in a given year than the year before and the speed at which that data arrived was also faster than the year before. But variety was something new.
Before big data showed up in the scene, data always meant structured data and was associated with a schema – for example, data managed by RDBMS. Semi-structured (computer logs from a data center) and unstructured(emails) existed before the days of big data but they did not have or were perceived not to have the same value as structured data. The perception was – Structured data can be monetized with the help of BI tools but data with some or no structure cannot be. It was either because such data had no inherent insight to offer or there were no means to gain those insights.
That changed in the internet era. Armed with semi/unstructured data processing technologies, the likes of Google and Facebook demonstrated that the seemingly meaningless data had, in fact, value only if you had the right technology to process such data. Other organizations like banks and telecom service providers who were sitting on a huge variety of data took notice and the era of Big Data was born. Companies are discovering that they have big data with high Volume, Velocity and Variety and want to monetize them using big data technologies. Few have been successful; some have been on the proverbial one step forward and two back mode of progress and others have quit trying. More on that later.
As volume, velocity and variety of data were increasing, newer ways of processing data came into play. The first word that flashes in the mind of anyone with faint familiarity of Big Data is Hadoop. Quite simply put, Hadoop is a distributed compute platform based on a distributed file system. That is, it uses a cluster of compute nodes with associated storage to process large volumes of data. In Hadoop, MapReduce is the compute engine, HDFS is storage and YARN is used to manage resources. There are claims made that Hadoop (and with it, Big Data) is dead. Those claims are not exactly true. There are newer processing technologies like Apache Spark, Tez and so on but one or more fundamentals of Hadoop is still prevalent in Big Data processing and Big Data solutions are being adopted in more and more organizations.
Typically, in the enterprise data world, BI tools were used to extract insights to plan the future. These BI operations were done in data warehouses (think Costco) or in data marts (think Discount Tire). A data warehouse is where all actionable business data from everyday operations of an organization is stored for future BI needs. A data mart can be considered as a mini-me of an EDW where, let us say, sales related data is stored for consumption by the sales department
In the big data world, given the variety, velocity and volume of data, a new storage architecture centered around a Data Lake is used widely.
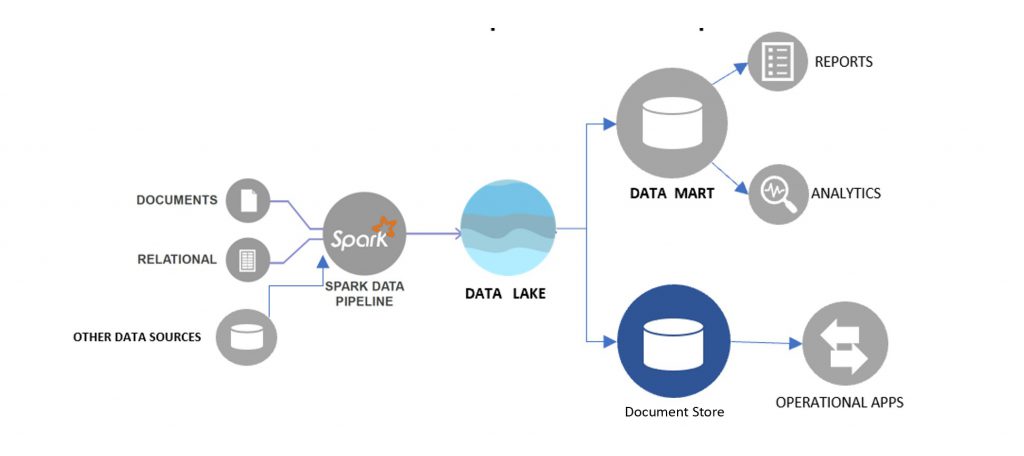
As shown in the figure an ingest pipeline (in this case using Spark) is used to hydrate the Data Lake with Data from various sources. Data Lakes when compared to a Data Warehouses have a flatter storage architecture. Ingested data is stored in its raw native format in a data lake in a logical zone called the raw zone. The data can then be cleansed, accessed for quality, curated and stored in another logical
zone called the standardized (or golden) zone. The data in the standardized zone is the one that is fit for consumption. They can be transformed as needed and loaded into one or more consumption zones like Data Mart or another store for a specific use case.
In next few blogs we will address Big Data, Big Data Technology and Data Lake in detail.
Fill in your details to experience Needletail in action