
Water, water, everywhere,
And all the boards did shrink;
Water, water, everywhere,
Nor any drop to drink.
– Samuel Taylor Coleridge, The Rime of the Ancient Mariner
Today we see more and more enterprises looking to build Data Lakes to become data driven organizations. They spent or are spending or planning to spend anywhere from a few million dollars to billions of dollars in this endeavor. Some of them had some degree of success and some have failed and others have taken a step back. Even those who failed or took a step back are considering reentering the foray.
A data lake is simply a central repository of all enterprise data. By all enterprise data, we mean Structured, Semi-Structured and Unstructured Data. This repository will hold your customer support emails, chats, data from enterprise systems such as OLTP, CRM & ERP, IoT device events, images, videos and so on. The goal for any organization is to get actionable insights and inferences from the data stored in a Data Lake.
Data Lakes are important as they can help derive insights from either individual data sets or from some combination of structured, unstructured and semi-structured data. Analytics based on machine learning over log files, social media, and IoT help identify, and act upon opportunities quicker, thereby increasing customer stickiness, ramping up efficiency, proactive maintenance, and making decisions.
When one reads the definition of Data Lake, it is quite normal to compare it to a Data Warehouse. Data Warehouses are optimized Databases for analyzing relational data coming from transactional systems and business applications. They are extremely fast and also expensive but are excellent for the purpose they are built and used for. One thing they cannot do is handle semi-structured and unstructured data.
Data Lakes on the other hand use relatively cheap storage and can handle all types of data. The query results are fast but not as fast as Data Warehouses. Also, while Data Warehouses host highly curated data, Data Lakes host both curated and uncurated Data.
Often, we observed that organizations commit the mistake of trying to build a Data Lake as a substitute for Warehouses. This is not a good approach today but things may change in the future.
In an attempt to build Data Lakes, some enterprises end up with what is called a Data Swamp. A Data Swamp is an unusable Data Lake or a Data Lake that does serve most of the original objectives. There are several reasons why enterprises end up with a Data Swamp but one main reason is the how the Lake is organized. Also, a Data Lake isn’t just a repository of data, but a repository of data that:
Most importantly, the end goals of building a Data Lake should be clearly defined and every effort should be made not to compromise those objectives in any of the steps involved in building your lake.
A Data Lake can be visualized as layers. From physical storage to a distributed file system like HDFS and files of various formats from the well-known like CSV, XML and JSON to the not so well known like parquet, ORC and AVRO.
ORC, Parquet and AVRO are optimized file formats used in Big Data environments. ORC and Parquet are columnar databases and AVRO is row based and each have their unique advantages. Choice of your file format is an important decision and is to be based on the nature of data and the queries that will be executed on them.
Unstructured data can be stored as it is in their native format. If necessary, they can be transformed to a structured format but a copy of data in the source format (raw data) is still maintained in a lake to support the schema on read paradigm.
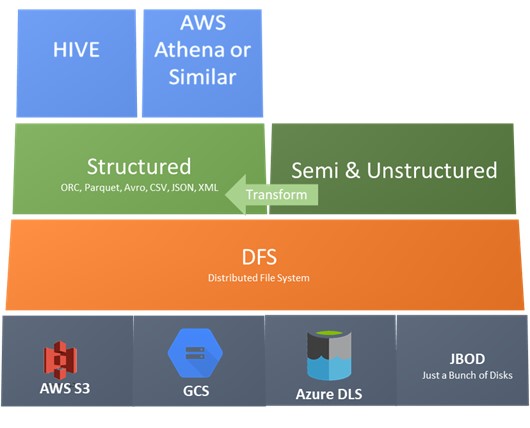
On top of structured data, a layer that provides querying capabilities on structured data is used. Apache Hive is one and similar tools are available from all major cloud service providers. These tools use Big Data processing technologies like MapReduce/Tez to execute the queries.
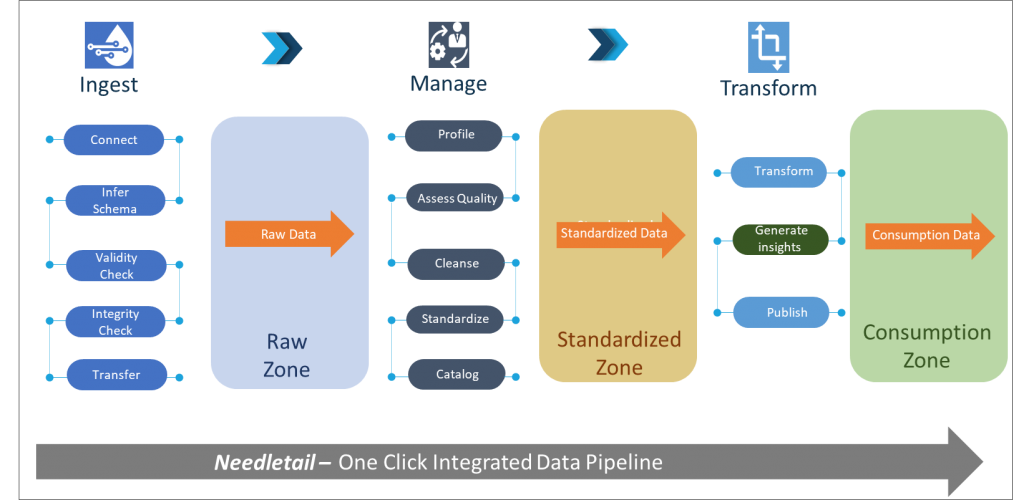
When we help our customers build their Data Lake, we guide them to implement it in Zones. That is, depending on the current status of the data at rest, we store them in logical zones.
Data ingested from sources with almost no processing performed on it, is stored in the Raw Zone. The Raw Zone data can be considered as a single source of truth as far as the lake is concerned. Applications that have not been conceived yet will have a source of historical data to operate on in the Raw Zone.
Standardized Zone also sometimes called Golden Zone, has data that has been accessed for quality, is cleansed, standardized (harmonized) and cataloged. The source for data in this zone is the Raw Zone.
Consumption Zone is transformed Data that is ready for consumption. The transformation is defined and requested by the end user or application that is going to consume the data. The consumption zone may extend outside of the Data Lake. That is, an external Data Mart can be the destination for consumption data and it may be outside the logical boundary of the Lake. Machine learning models also source data from this zone.
Our Data Lake Management platform, Needletail defines actions that are performed before data lands in a given Zone and enforces consistent process governance as shown below:
An enterprise will be best served by seasoned architects who have successfully built Data Lakes as it can become a costly and never-ending exercise.
Fill in your details to experience Needletail in action